Why Data Architecture Matters for Modern Applications
Modern applications are only as powerful as the data infrastructure behind them. As businesses generate and process increasing volumes of information, robust data architecture—including data pipelines, data lakes, and scalable storage systems—has become essential for performance, analytics, and AI-driven innovation. In this blog, we explore why a well-designed data architecture is the foundation of intelligent, scalable applications. Learn how modern data systems enable real-time insights, seamless scalability, and better decision-making, and discover how AtumCode builds data-driven solutions that empower businesses to grow with confidence.
BACKEND DEVELOPMENTCUSTOM SOFTWARE DEVELOPMENTMOBILE APP DEVELOPMENTAI
Srushti M.
6/2/20267 min read
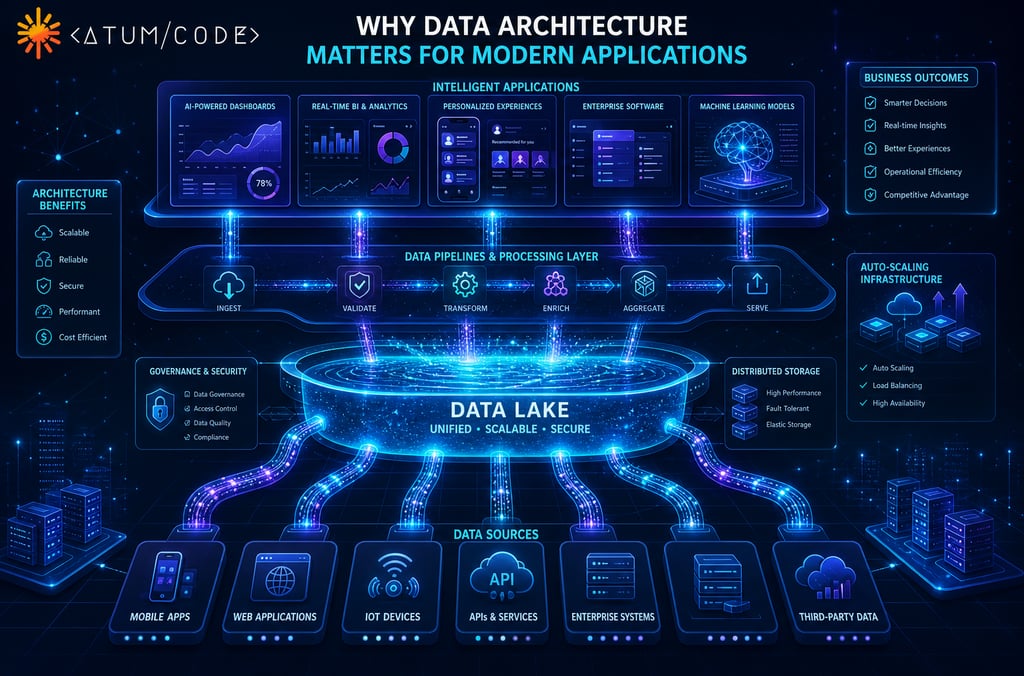
Understanding Data Architecture
Data architecture serves as a blueprint that outlines how data is collected, stored, and utilized within applications. It includes a combination of models, policies, and procedures that govern data management, making it a critical aspect of modern application development. With the exponential growth of data, a well-defined data architecture ensures that organizations can derive meaningful insights from the information they generate and accumulate.
A fundamental component of data architecture is the data model, which defines the structure of data elements and the relationships between them. It acts as a framework for understanding how data is organized, accessed, and transformed. Different types of data models—including conceptual, logical, and physical models—are employed to meet specific requirements. Each model serves a unique purpose, enabling developers to visualize data and supporting effective communication among stakeholders.
Moreover, metadata management plays a significant role in enhancing data architecture. Metadata refers to the data about data; it provides context, definitions, and information about the data itself. By managing metadata effectively, organizations can ensure data quality, compliance, and accessibility. This aspect is particularly crucial in modern applications, where decisions are often based on real-time data analysis.
In addition to data models and metadata, data storage options are another key element of data architecture. Organizations can choose from a variety of storage solutions ranging from traditional database management systems to cloud-based options and data lakes. The choice of storage impacts scalability, performance, and cost-efficiency, influencing how effectively data can be managed within an application.
In summary, understanding the foundational aspects of data architecture, including data models, metadata management, and storage solutions, is essential. As modern applications increasingly rely on data-driven decision-making, a robust data architecture enables them to function efficiently and effectively.
The Role of Data Pipelines in Modern Applications
In the landscape of modern application development, data pipelines play a critical role in facilitating efficient data transfer from various sources to applications, thus ensuring seamless functionality. A data pipeline is essentially a series of data processing steps that encompass the extraction, transformation, and loading of data, commonly referred to in the industry as the ETL process. This process is foundational in enabling applications to access and utilize data effectively.
Data integrity is paramount in application development, and this is where data pipelines prove invaluable. By systematically managing data flows, a pipeline helps maintain the quality and consistency of the data being processed. This ensures that the applications are operating on reliable and accurate information, thus enhancing decision-making processes and overall performance. Furthermore, data pipelines support the integration of multiple data sources, which is essential in today’s multi-faceted data environment.
Real-time access to data has become increasingly vital for many applications, particularly those in sectors such as finance, healthcare, and e-commerce, where timely information can drive competitive advantages. Data pipelines facilitate this real-time processing by enabling data streaming—an approach that allows continuous input of data. As data flows in, it can be instantly transformed and made accessible to the applications needing it. This capability is particularly beneficial for applications relying on immediate insights to respond swiftly to changing conditions.
In addition to real-time analytics, the integration of various data sources through robust data pipelines allows applications to pull in contextually relevant information, enriching the data landscape. The ability to automate the flow of data from disparate sources into a unified format empowers organizations to harness their data effectively, leading to enhanced application functionality and user satisfaction.
Exploring Data Lakes
Data lakes have emerged as a revolutionary element in modern data architecture, providing organizations with a flexible and scalable approach to storing large volumes of diverse data. Unlike traditional databases which primarily manage structured data, data lakes can accommodate unstructured, semi-structured, and structured data, making them particularly well-suited to the demands of contemporary applications.
In a conventional database environment, data is typically organized into tables and schemas, requiring pre-defined structures. This can limit an organization’s ability to adapt to new data types or analysis needs. On the other hand, data lakes allow for the storage of raw data in its native format without the need to define a schema upfront. This makes data lakes an attractive alternative for organizations aiming to harness the power of big data.
One of the primary advantages of utilizing data lakes lies in their scalability. As data continues to grow exponentially, organizations require systems that can easily scale to accommodate this influx. Data lakes provide a cost-effective solution by leveraging inexpensive storage options, thus allowing businesses to store vast amounts of data without incurring significant expenses. This aligns well with the trend of increasing data availability and diversity, particularly in fields such as IoT, log management, and AI analytics.
Furthermore, the agility that data lakes offer cannot be overstated. Organizations can quickly ingest data from various sources, enabling them to respond to new business needs with exceptional speed. This adaptability supports a data-driven approach, where insights can be extracted live, fueling automated decision-making and analytics processes.
In conclusion, data lakes represent a pivotal advancement in data architecture. By providing a modern solution for handling unstructured and semi-structured data, they not only enhance flexibility and scalability but also ensure organizations can navigate the complexities of the modern data landscape effectively.
Building Scalable Data Systems
In today's fast-paced digital landscape, the scalability of data systems is critical to ensuring that applications meet the ever-increasing demands of users. Scalable data systems are designed to effectively handle large volumes of data and user requests without sacrificing performance. To achieve scalability, two main strategies are generally employed: horizontal scaling and vertical scaling.
Horizontal scaling, often referred to as scale-out, involves adding more machines or nodes to a system to distribute the load evenly. This approach is particularly effective in cloud environments, where adding resources can be done seamlessly. By leveraging distributed data storage systems, organizations can enhance their capacity while maintaining availability. On the other hand, vertical scaling, or scale-up, involves upgrading the existing hardware with more powerful components, such as processors, memory, and storage. Although vertical scaling can be simpler to implement initially, it has inherent limitations due to physical constraints of a machine.
Cloud-based solutions play a pivotal role in achieving scalability for modern applications. They provide on-demand resources, allowing organizations to respond quickly to fluctuations in workload. Cloud providers offer diverse services, such as databases designed for scalability and performance optimization, making it easier for organizations to adopt microservices architectures that thrive in distributed environments. This cloud infrastructure not only accommodates growing data volumes but also improves system resilience, redundancy, and disaster recovery capabilities.
The design of scalable data systems ultimately impacts an application's overall performance and availability. By strategically implementing horizontal and vertical scaling along with utilizing cloud technologies, businesses can create robust infrastructures that support growth. Organizations that prioritize scalability in their data architecture are better positioned to handle increasing data loads while delivering consistent and efficient user experiences.
Data Infrastructure for Intelligent Applications
In the era of digital transformation, robust data infrastructure is pivotal for the development of intelligent applications. Such applications leverage data to enhance performance, offering functionalities that employ machine learning (ML) and artificial intelligence (AI) techniques. A well-structured data architecture serves as the backbone for these technologies, ensuring that the necessary data flows seamlessly and is easily accessible for processing.
Effective data architecture is instrumental in transforming raw data into actionable insights. By utilizing appropriate data storage solutions and processing frameworks, organizations can facilitate advanced analytics on large datasets. This capability is crucial for intelligent applications that depend on real-time data analysis to make informed decisions and adapt to user behavior dynamically. For instance, ML algorithms require meticulously organized data to train models accurately, highlighting the importance of having a scalable and efficient data pipeline.
Key technologies that bolster intelligent data processing include cloud computing, distributed databases, and advanced data management systems. These innovations not only streamline data access but also enhance the ability to integrate and analyze diverse data sources, further powering ML and AI features. Tools such as Apache Kafka and Apache Spark exemplify how modern data architectures enable the processing of vast amounts of data with speed and efficiency.
Furthermore, adopting a microservices architecture can significantly improve application responsiveness and reliability. This approach allows intelligent applications to execute specific tasks independently, optimizing overall performance through better resource allocation. By aligning data infrastructure with the application’s needs, organizations can create smart functionalities that improve user experience and operational efficiency.
Challenges in Data Architecture Design
Organizations today face several challenges when designing effective data architecture, which can significantly impact their ability to leverage data for informed decision-making. One of the primary hurdles is the existence of data silos. These silos occur when different departments or teams within an organization store data independently, without integrating or sharing it with others. This fragmented approach can lead to inconsistent data sets and hinder a holistic view of the organization's information. Addressing data silos requires a collaborative mindset and strategies to promote data sharing across the organization.
Another significant challenge is ensuring data quality. Poor data quality can arise from inconsistent data entry processes, lack of validation, or outdated information. Organizations must implement robust data governance frameworks that establish standards for data accuracy and reliability. Attention to detail in these frameworks is crucial to mitigate issues related to incorrect data, as well as to maintain the integrity of analytics and reporting processes.
Compliance and security concerns also play a vital role in the data architecture design. With increasing regulations surrounding data privacy, such as the General Data Protection Regulation (GDPR), organizations must ensure their data practices comply with legal standards. Additionally, safeguarding sensitive information from unauthorized access or breaches is paramount. This necessitates incorporating data encryption, access controls, and regular security audits into the architectural strategy.
Lastly, the complexity of integrating diverse data sources presents another challenge. Organizations often utilize a variety of data formats and platforms, ranging from relational databases to cloud storage solutions. Creating a unified data architecture that seamlessly integrates these sources can be complex and requires careful planning and execution. Employing modern integration tools and techniques can aid in streamlining this process, ensuring that all data sources can effectively communicate and work together.
Future Trends in Data Architecture
The future of data architecture is rapidly evolving, influenced by the increasing complexities of modern applications and the demand for real-time data insights. One notable trend is the emergence of data mesh architecture, which decentralizes data ownership and promotes cross-functional teams managing their data domains. This approach encourages innovation and scalability while ensuring that data remains accessible across various departments. As organizations adopt data mesh frameworks, traditional centralized data management systems may increasingly be supplanted by more flexible, collaborative structures.
Another significant trend in data architecture is the growing emphasis on data governance. With the proliferation of data sources and the strict regulatory environment surrounding data privacy, organizations are prioritizing robust governance frameworks. Effective governance ensures data quality, compliance, and security, enabling businesses to leverage information responsibly and ethically. In this context, businesses are implementing advanced tools and methodologies to monitor and maintain data integrity across all layers of their architecture, which is crucial for making informed decisions.
Additionally, the evolution of cloud-based data solutions will shape the future landscape of data architecture. As more companies transition to cloud environments, they are tapping into scalable, cost-effective storage and processing options. The rise of hybrid and multi-cloud strategies allows organizations to optimize their data architectures, balancing performance, availability, and security. Moreover, emerging technologies like artificial intelligence and machine learning are driving innovation in cloud data services, enabling real-time analytics and predictive insights that can enhance application performance.
As these trends gain traction, we can anticipate a future where data architecture becomes increasingly integral to the development of scalable, intelligent applications. Organizations that stay ahead of these trends will position themselves as leaders in their respective industries, leveraging data as a strategic asset for driving growth and innovation.
Connect With Us
Your partner in custom software solutions and design.
Innovate Today, Reach Out!
contact@atumcode.com
+1 202 292 4041
+91 801 091 1708
© 2026. All rights reserved.
Warje, Pune 411058, Maharashtra, India
AtumCode Solutions Pvt. Ltd.
Beyond Code, Building Vision!
D&B D-U-N-S Number : 76-637-9675